Authors:
(1) Jonathan H. Rystrøm.
Table of Links
3 Methods and Data
3.1 Defining Barrier-to-Exit
On a high level, Barrier-to-Exit measures how much effort users must expend to signal that their preferences have changed (Rakova & Chowdhury, 2019). It is defined in terms of how quickly users’ revealed preferences for a specific category change between interaction thresholds. In this section, we will motivate the intuition for Barrier-to-Exit as well as formalise the concept within the context of Amazon’s recommender system.
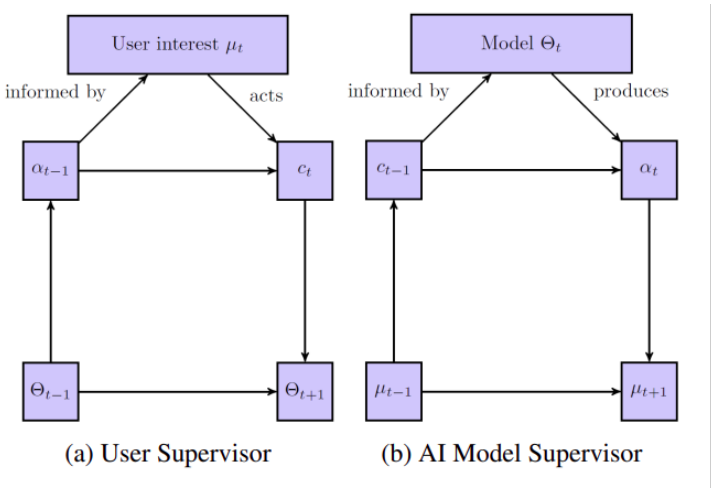
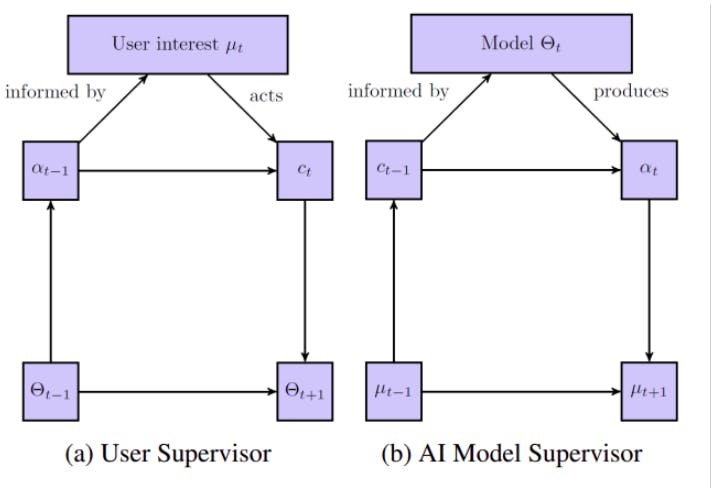
To understand the role of Barrier-to-Exit and how it can be calculated from ratings, let us consider a diagram of the interaction between the user and recommender system (”AI Model”) as seen in Fig. 1.
Both diagrams (a) and (b) show feedback loops with the user and the model, respectively, as ”supervisors”. The juxtaposition shows the double-sided interaction as argued in Jiang et al. (2019). The diagram has multiple elements: µ is user interest, Θ is the Model, α is the shown recommendations, and c is the revealed preferences (i.e. the signal the model uses to update recommendations). The subscripts denote timesteps going from left to right.
While the diagram acts as a conceptual framework for understanding the interaction, we must consider which parts we can measure and which parts we need to model. Rakova and Chowdhury (2019) argue that by only analysing how revealed preferences change over time, we can calculate a measure of the effort required to shift preferences; the Barrier-to-Exit.
Note that while the overall feedback loop concerns the whole model, Barrier-to-Exit is defined per category. Categories can be genres, such as ”Thriller” or ”Science Fiction”, or book types such as ”Self-help” or ”Cook Book”. Each book can have several categories.
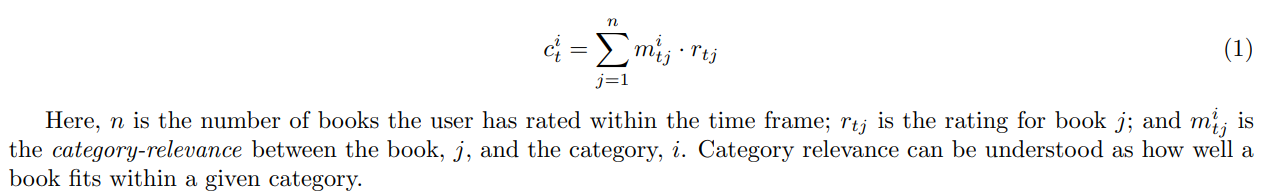
The category relevance is not an automatically available feature of our data (see 3.2). In contrast, Rakova and Chowdhury (2019) use the MovieLens dataset (Harper & Konstan, 2016), where category-relevance has been manually annotated for a subset of the data. This makes it possible to use (semi-)supervised learning to annotate the rest of the data (i.e. Kipf & Welling, 2017).
Unfortunately, the Amazon data has no labels. Instead, we use an unsupervised approach based on category co-occurrence. Books are given a high category relevance for a specific category if they belong to categories that often occur together. For example, a book with the categories ”thriller” and ”horror” would have a category-relevance score of 1 for ”thriller” if it always co-occurs with ”horror”, but a score of 0 for ”gardening” if it never co-occurs with ”gardening”. We normalize the scores so they range from 0 to 1. See the GitHub repository for implementation details.
We now move on to interaction thresholds (Rakova & Chowdhury, 2019). Conceptually, interaction thresholds are the users’ range of preferences within a given category. If, say, a user only ever rates thrillers 4 stars but rates some cookbooks 1 star and others 5 stars, they would have narrow interaction thresholds for thrillers and broader interaction thresholds for cookbooks.

There are some important things to note about the definition of Barrier-to-Exit. First, there can be multiple values of Barrier-to-Exit per user and category. Every time a user has a preference within a category that goes from above the interaction thresholds to below, a Barrier-to-Exit for that period is defined.
Second, Barrier-to-Exit defines users who change preferences. Changing preferences are defined as users going from above the interaction thresholds to below the interaction thresholds.
Third, Barrier-to-Exit cannot be exactly zero. This is because it is only defined when a user has intermediate ratings between the thresholds. If a user has a rating that goes above the interaction thresholds and the next one is below, this would not register in Barrier-to-Exit.
Finally (and crucially), Barrier-to-Exit is only defined for a subset of users. Having a well-defined Barrier-to-Exit for a user requires both a) enough ratings and b) that these ratings change relative to a category. We can thus only draw inferences for this subset of users. We will discuss the implications of this further in the discussion (section 5.2).
In this section, we have provided a mathematical formulation of Barrier-to-Exit along with important caveats. For the code implementation, please refer to repository.
3.2 Data
For this analysis, we use a dataset of Amazon book reviews (Ni et al., 2019). The raw dataset consists of approximately 51 million ratings by ca. 15 million users in the period 1998 to 2018[2]. All the ratings are on a 1-5 Likert scale.
The dataset was scraped from the Amazon Web Store building on the methodology of McAuley et al. (2015). Unfortunately, since the dataset lacks a datasheet (Gebru et al., 2021), it is difficult to figure out whether it has any issues with coverage or bias. It also makes it harder to replicate the data collection from scratch. Other than that, the dataset is easily accessible and well documented.
One coverage-related aspect we need to be aware of is that we are using ratings as a proxy for interactions. In the dataset, we do not have access to people who bought a product but did not rate it, nor people who neither bought a product nor rated it. This gives us quite an indirect measure of the actual recommendation process - particularly compared to the MovieLens dataset (Harper & Konstan, 2016; Rakova & Chowdhury, 2019).
Because of the size of the data, pre-processing becomes non-trivial. An explanation of the necessary steps can be seen in appendix C.
While the original dataset is large, we are only interested in a subset. Specifically, we are interested in users who have changed their preferences. Therefore, we filter to only include users with more than 20 ratings, which follows the conventions in MovieLens (Harper & Konstan, 2016) for which Barrier-to-Exit was originally defined (Rakova & Chowdhury, 2019).
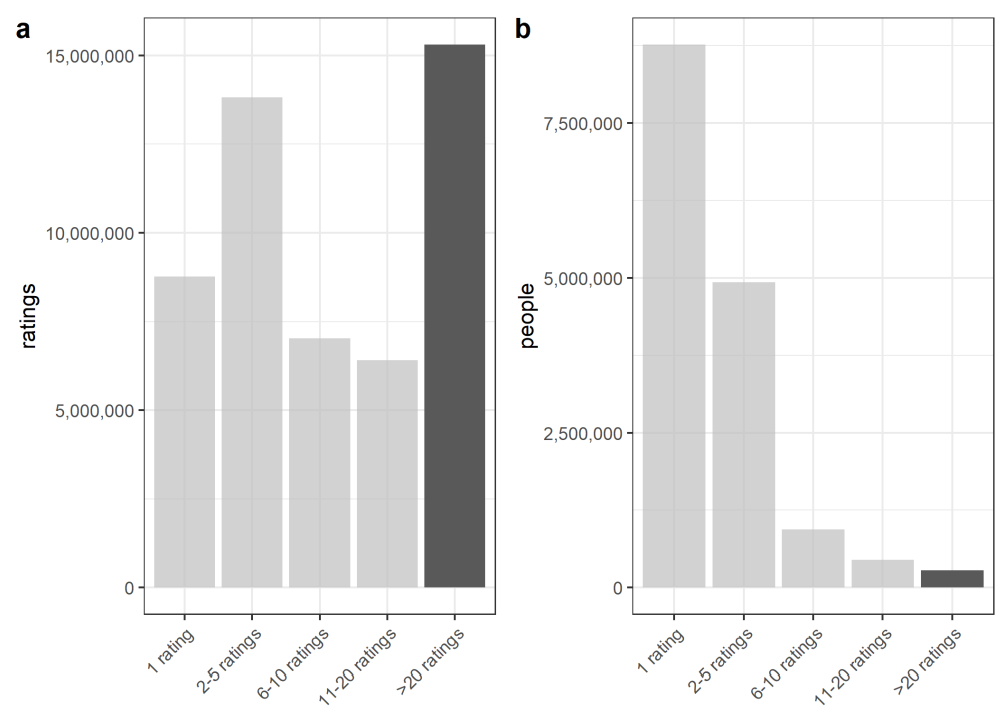
Fig. 2 shows the selected subset. It is worth noticing that while our subset retains a substantial fraction of the ratings (≈ 30%), we only retain ca. 350,000 users (0.6%). This is typical for user activity, which tends to be fat-tailed (Papakyriakopoulos et al., 2020). We will discuss the implications for our interpretation in the discussion (5.2).
As we will later see, only a fraction of these has changed preferences according to our definition (see section 3.1).
For our final analysis, we have 50,626 users which fit our definition (≈ 0.1% of the total).
The rating dataset was merged with a dataset providing categories for each book. The category dataset was from the same source (i.e. Ni et al., 2019). To keep the computations simple for calculating category-similarity (see code on GitHub), we only consider categories that have been used on more than 100 books. This approach is valid because the distribution of categories is heavily skewed, meaning that a small number of categories are used on a large number of books. (This is a similar dynamic to user activity; see Fig. 2).
3.3 Model
Now that we have operationalised Barrier-to-Exit as a measure of the difficulty to change preferences, let us introduce the statistical model for analysing the trend.
The first thing to note is that we need a crossed multi-level model (Baayen et al., 2008). Our model should have two levels: user and category. The user level is the most theoretically obvious one. Since each user can have multiple preference changes (with associated Barrier-to-Exit), we should control for their individual differences (Baayen et al., 2008). This is also important as the recommender system will use predictive features that are not accessible in the dataset (Smith & Linden, 2017).
Categories constitute the other level. The role of the category level in our model is to account for item-level features. As explained in the introduction, there are commercial (i.e. companies are following the prediction imperative; (Zuboff, 2019)) and algorithmic reasons (i.e. reducing variability could improve on reward objective (Carroll et al., 2022)) to believe that different categories will have different Barriers-to-Exit. Categories can therefore act as a proxy for these effects. This crossed design is often used within psychology research (Baayen et al., 2008).
There are two reasons to include categories as random effects and not fixed effects. The first is the number of categories. There are 300+ categories in our dataset. Modelling these as fixed effects would therefore be infeasible. Secondly, since there we use them as a proxy for item-level variance, it is more convenient to only model the random components (Maddala, 1971)
This gives us the following model:

A crucial thing to note is that log-transforming Barrier-to-Exit changes the interpretation of the coefficients. Instead of interpreting them on a linear scale, they should be interpreted on a logarithmic scale (Villadsen & Wulff, 2021). The most natural way to do this is to exponentiate the effects and interpret it as a percentage change. However, the transformation introduces statistical issues, which we will discuss in section 5.2.

It is also worth noting that activity level is relatively uncorrelated with time (see Fig. 3b. This is because activity refers to the activity within the Barrier-to-Exit period and not total activity on Amazon. The latter has increased substantially as can be seen by the density of the dots in Fig. 3b.
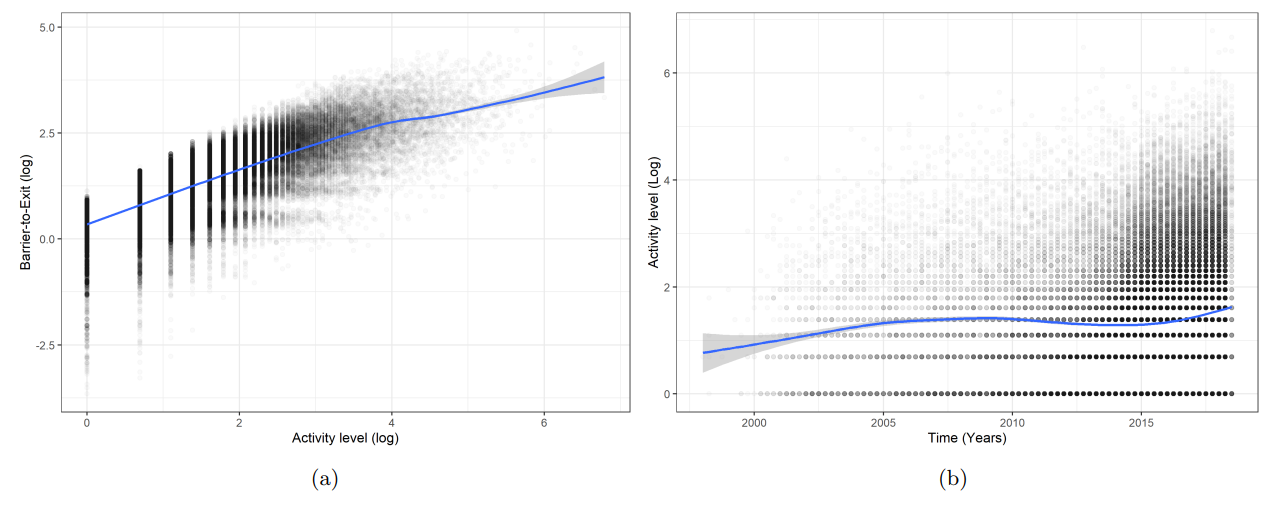
To assess validity, we test the assumptions for the model. For the full check see appendix A. There are a few violations worth noting: The residuals and random effects deviated from normality - particularly for the category-level random effects. However, this should have little influence on the estimation of the fixed effects (Schielzeth et al., 2020). Nevertheless, we run an additional analysis with the problematic categories removed to assess the robustness of the findings (see B.2).
3.4 Creating and testing hypotheses
To answer our research question in an inferential framework, we need to transform them into hypotheses with testable implications (Popper, 1970). We propose the following hypothesis:
• Hypothesis: There has been a significant increase in Barrier-to-Exit for the Amazon Book Recommender System in the period 1998-2018.
To test the hypothesis, we use Satterthwaite’s significance test from the lmerTest-package (Kuznetsova et al., 2017; Satterthwaite, 1946) to assess the coefficient for time (β1). However, it is important to note that the method of calculating degrees of freedom in mixed effects models (Satterthwaite, 1946) can inflate Type I errors when the sample size is small (Baayen et al., 2008). In our case, the sample size is large, so this is less of a concern.
The large sample size also implies p-values close to zero (Ghasemi & Zahediasl, 2012) for even small effects. Thus, we are also interested in the magnitude of the effect size, rather than just the significance.
Note, that the increase is a growth-rate instead of a linear increase. This affects how we interpret the magnitude of the effect size.
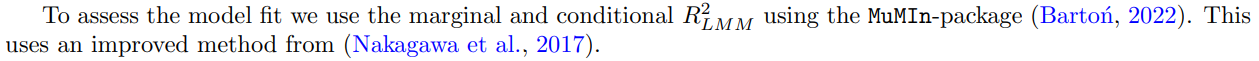
[2] For documentation see: https://nijianmo.github.io/amazon/index.html
This paper is available on arxiv under CC 4.0 license.