
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Oded Blumenthal, Software and Information Systems Engineering, Ben Gurion University, Israel;
(2) Guy Shani, Software and Information Systems Engineering, Ben Gurion University, Israel.
Table of Links
- Introduction
- Background
- Related Work
- POMCP for Stochastic Contingent Planning
- Domain Independent Heuristics for POMCP
- Empirical Evaluation
- Conclusion and References
6 Empirical Evaluation
We conduct an empirical study to evaluate our methods. Our methods are implemented in C#.
6.1 Benchmark Domains
We extended the following contingent planning benchmarks to stochastic settings:
Doors: In the door domain the agent must move in a grid to reach a target position. Odd levels in the grid are all open, while in even levels there are doors, and only one door is open. The agent can sense whether a door is open when it is at adjacent cells. The agent must identify the open doors and get to the target position. In the stochastic version the agent can open a closed door with some probability of success. The agent can hence either search for the already open door, or attempt to open a closed door.
Blocks World: In the contingent blocks world problem, the agent does not know the structure of the initial block configuration, but it can sense whether one block is on top of another one, and whether a block is clear. In the stochastic version moving a block from one block to another has a 0.3 probability of success, while moving blocks to and from the table succeeds deterministicly. Hence, it is often preferable to use the table as an intermediate position.
Unix: In this domain the agent must search for a file in a file system, and copy it to a destination folder. In the stochastic version there is a non-uniform distribution over the possible locations of the file.
MedPks: The agent here needs to identify which illness a patient has and treat it. To do so, the agent tests for each illness independently, until the proper illness is found. The stochastic version here has non-uniform distribution over the possible illnesses as well.
Localize: In this domain the agent must reach a goal position in a grid. The agent does not know where it initially is, and can only sense adjacent walls. In the stochastic version there several places in the grid where the agent may slip and stay in place. This makes the localization in the grid more difficult.
Wumpus: In this challenging problem the agent must reach a target position in a grid infested by monsters called Wumpuses. Cells may be unsafe to travel as they may contain either a Wumpus or a pit. Wumpuses emit a stench, and pits emit a breeze, both of which can be sensed in adjacent cells. The agent must sense in multiple positions to identify the safe cells. The stochastic version here also has non-uniform distribution over the safe cells.
6.2 Results
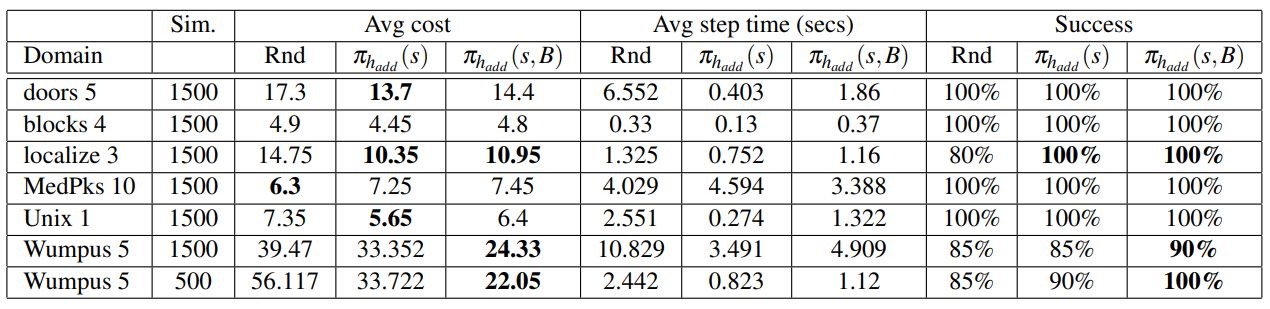
For each domain above we run 20 online episodes, and compute the success rate, the average run time for computing the next action, and the average cost to the goal. We did not use a timeout, but runs longer than 100 steps were considered to be stuck in a loop, and terminated.

We begin by looking at the quality of the policy — the average cost to the goal. As can be seen, the random rollout policy is best only in the MedPks domain, and close to best in unix. This is not too surprising, because in these two domains the best strategy is very simple, and random strategies easily stumble upon the goal. In blocks all methods achieved similar performance, because the optimal strategy is very short, and rollouts are less important. This domain has many possible actions, and hence a huge branching factor, making it difficult to scale up using POMCP.
On doors and localize, which require lengthier trajectories to reach the goal, but do not need long information-gathering efforts, the single state hadd strategy operates very well. However, on Wumpus, where long sequences of actions are needed for information gathering, the multiple-state heuristic works best. We expected the results to be that way, although we expected more significant difference between the "smart" heuristics and the random rollout.
With respect to the required time to run the simulations for a single decision, the results are mixed. While obviously the random strategy requires no time to compute the next action during a rollout, it often results in lengthy rollouts, which reduce this effect. The single state heuristic is almost always faster than the multi-state heuristic, but not by much.