This is paper is available on arxiv under CC 4.0 DEED license.
Authors:
(1) Dhruv Shah, UC Berkeley and he contributed equally;
(2) Michael Equi, UC Berkeley and he contributed equally;
(3) Blazej Osinski, University of Warsaw;
(4) Fei Xia, Google DeepMind;
(5) Brian Ichter, Google DeepMind;
(6) Sergey Levine, UC Berkeley and Google DeepMind.
Table of Links
- Abstract & Introduction
- Related Work
- Problem Formulation and Overview
- LFG: Scoring Subgoals by Polling LLMs
- LLM Heuristics for Goal-Directed Exploration
- System Evaluation
- Discussion and References
- A. Implementation Details
- B. Prompts
A Implementation Details
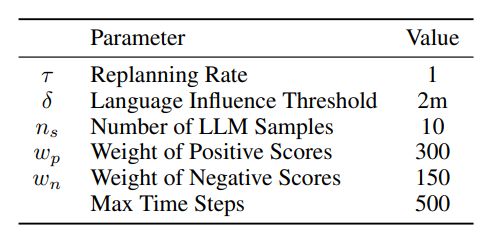
A.1 Hyperparameters
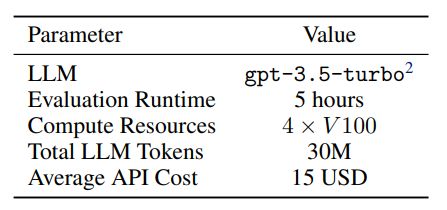
A.2 Computational Resources
A.3 Real World Results
Generating Prompts: For both topological and geometric maps we use hand engineered methods for clustering objects in ways that the LLM can efficiently reason over. For geometric maps we implement two functions: parseObjects and clusterObjects. In our implementation, parseObejcts filters the geometric map and identifies the cluster centers among each class. clusterObjects takes the cluster centers and performs agglomerative clustering with a threshold of 6 meters, which is roughly the size of one section of a standard house. For topological maps we rely on the configuration of the four cameras to automatically perform parsing and clustering. In our implementation all the objects detected in each frame from either the front, left, right, or rear facing cameras is considered a single cluster.
Perception: For the hardware, we use a locobot base with a four HD logitech web cameras that are positioned at 90 degrees relative to each other. At each step of LFG each of four cameras is recorded and frames are semantically annotated. LFG directly uses these frames to determine if the robot should continue to move forward, turn left, turn right, or turn around a full 180 degrees. To improve the performance of our system we choose to whitelist a subset of the 20,000 classes. This reduces the size of the API calls to the language models and helps steer the LLM to focus on more useful information. Following is the complete whitelist used in our experiments:
• toaster
• projector
• chair
• kitchen table
• sink
• kitchen sink
• water faucet
• faucet
• microwave oven
• toaster oven
• oven
• coffee table
• coffee maker
• coffeepot
• dining table
• table
• bathtub
• bath towel
• urinal
• toilet
• toilet tissue
• refrigerator
• automatic washer
• washbasin
• dishwasher
• television set
• sofa
• sofa bed
• bed
• chandelier
• ottoman
• dresser
• curtain
• shower curtain
• trash can
• garbage
• cabinet
• file cabinet
• monitor (computer equipment)
• computer monitor
• computer keyboard
• laptop computer
• desk
• stool
• hand towel
• shampoo
• soap
• drawer
• pillow
Low-level Policy: The low-level policy running on the robot is the NoMaD goal-conditioned diffusion policy trained to avoid obstacles during exploration and determine which frontiers can be explored further [41].
High-level Planning: For real-world experiments, we follow the setup of ViKiNG [34], where the agent runs a simple frontier-based exploration algorithm and incorporates the LLM scores as goaldirected heuristics to pick the best subgoal frontier. For simulation experiments, we use a geometric map coupled with frontier-based exploration, following the setup of Chaplot et al. [38]. Algorithms 3 and 4 summarize the high-level planning module in both cases.

A.4 More Experiment Rollouts
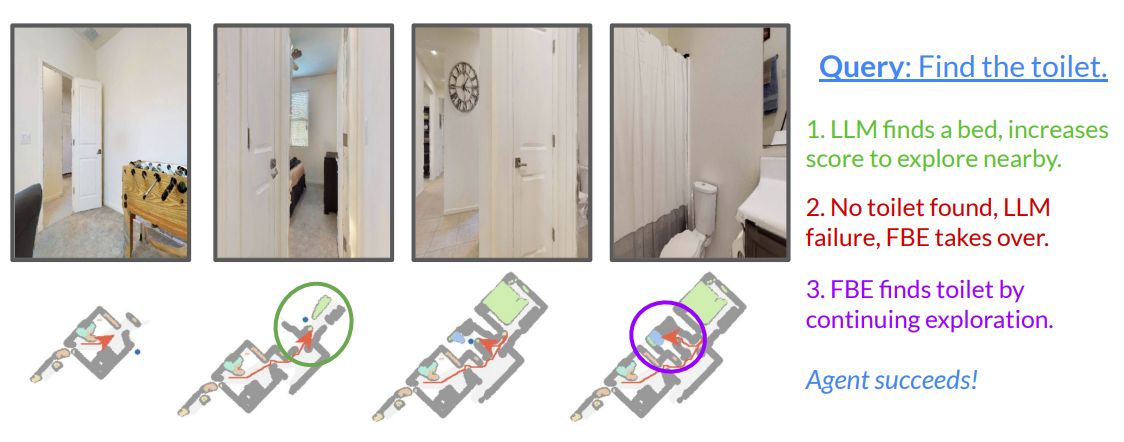
Figure 6 shows an example where the negative scoring is essential to LFG’s success. Figures 7 and 8 show examples of LFG deployed in a previously unseen apartment and an office building, successfully exploring the environments to find an oven and a kitchen sink.