
In the spirit of the Mechanistic interpretability agenda for neural networks, this post (and perhaps others to follow in a series) investigates the “algorithms” learned by a transformer model for tackling a narrow technical task —a modified version of the “Valid Parentheses” Leetcode problem.
While the utility of the task is much more modest in scope than the more general next-token prediction you’d expect in an LLM, the exercise will help us explore some of the early intuitions, investigative tools, and general epistemological methodologies typically deployed to know what models are doing (and how we know they are.)
The ARENA Mechinterp monthly challenges were a huge influence on this post, and the first set of problems will come from there. (You should definitely check out the program.)
Series structure:
- Pick a Leetcode problem as a task. (Part 1)
- Train a minimum viable Transformer model on it. (Part 2)
- Investigate what the model learnt. (Part 3)
Part 1: Problem
The Valid Parentheses problem as seen on Leetcode:
Some modified constraints on the problem we’ll be using for the task:
- The only acceptable characters are “(” and “)”
-
This removes the need to handle cases like "([)]”.
-
- The maximum input sequence is 40 characters long.
- To help keep our model small for quick iterations.
Examples
“(((())))” → Valid
“()()()(” → Invalid
“)()()()(” → Invalid
Vanilla Solution
def isValid(self, s: str) -> bool:
nesting_depth = 0
for bracket in s:
if bracket == '(':
# An opening bracket increases unresolved nesting depth
nesting_depth += 1
elif bracket == ')':
# A closing bracket decreases unresolved nesting depth
nesting_depth -= 1
# We don't expect to ever have negative unresolved nesting depth,
# so we can declare 'invalid' midway through the sequence if we see this
if nesting_depth < 0:
return False
# Final check that all open brackets were closed.
return nesting_depth == 0
Notes on failure cases:
-
nesting_depth ≠ 0 at the end of the sequence
“()()()((” → Invalid
For this, it’s not obvious anything is wrong till the very end when we see that the last opened brackets don’t have an accompanying bracket. The thing to note is that there is no point in the sequence, until the very end, where we had enough information to know something was off.
-
nesting_depth < 0 at any point in the sequence
example: “())()()(” → Invalid
In this case, on the other hand, there is enough information by the third position to know the validity of the sequence is irrecoverable, so we can call it quits early.
Something to note is that this example would have passed the first failure test as the
nesting_depthat the end would’ve been equal to 0. So this test case doesn't just help us stop early, it’s vital. The same applies to the first failure case example where it would have passed test 2.
Now, we don't expect an autoregressive transformer model to solve the problem the exact same way, given its architecture affords slightly different mechanisms than looping through the sequence once and checking if all is well. However, we know for sure that the transformer architecture (and other sequence processing architectures) are at least able to discover and process information about all elements in a sequence. It’s important to remember that while the solution may look different, the structure of the problem is the same and the hard bounds on what is known and where in the sequence continue to be true whether it’s a loop and if-statements or an ensemble of self-attention sweeps and MLP nonlinearities.
The interesting question then is just how this architecture leverages this information and if it’s easily discernible with the existing tooling; because it is unavoidable for a sufficiently performant solution of any architecture to not test for at least the above two failure cases.
This is one of the advantages of toy problems; we get a sufficiently understood narrow task with these hard guarantees which can help inform the investigation as we shall soon see.
Part 2: Data & Model
Training Data Preparation
Here are some target characteristics we’re going for with the data generation:
-
An equal number of balanced and unbalanced strings.
-
Strings will be of even length, as an odd-length string is obviously unbalanced; which would not be a very interesting heuristic for the model to learn.
-
All string lengths (2-40) should be equally likely.
-
For a given string length, all potential parentheses nesting depths should be equally likely.
A common theme is apparent: we’re trying to make every thinkable distribution statistic equally likely to reduce bias in any given direction, to ensure robustness and to deny obvious quick-win heuristics as an option for the model. For generating failure cases, we will first generate valid parentheses with the above-listed guarantees and then mutate half of them to get unbalanced.
from random import randint, randrange, sample
from typing import List, Tuple, Union, Optional, Callable, Dict
from jaxtyping import Float, Int
import torch as t
from torch import Tensor
import plotly.express as px
import einops
from dataclasses import dataclass
import math
def isValid(s: str) -> bool:
nesting_depth = 0
for bracket in s:
if bracket == '(':
# An opening bracket increases unresolved nesting depth
nesting_depth += 1
elif bracket == ')':
# A closing bracket decreases unresolved nesting depth
nesting_depth -= 1
# We don't expect to ever have negative unresolved nesting depth,
# so we can declare 'invalid' midway through the sequence if we see this
if nesting_depth < 0:
return False
# Final check that all open brackets were closed.
return nesting_depth == 0
assert isValid('()()((((()())())))') == True
assert isValid(')()((((()())()))(') == False
Data Generation Scheme #1: Random Walk
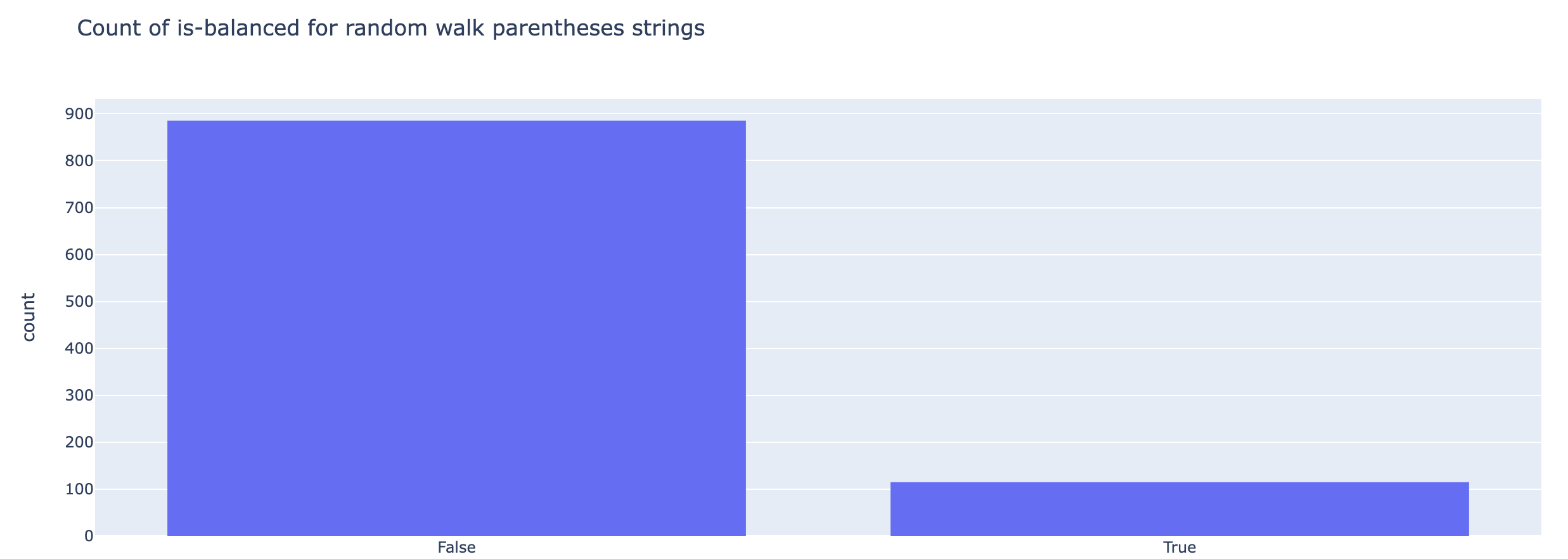
The first attempt at parentheses generation just does a random walk. But as you can see in the plots below the subspace of unbalanced parentheses is much larger than for balanced; so we’ll have to introduce stochasticity differently.
PARENS = ['(', ')']
def get_random_walk_parens(parens_num: int, length_range: Tuple[int]) -> List[str]:
range_start, range_end = length_range
random_parens = [
# Add 1 to make passed range_end inclusive
''.join(PARENS[randint(0, 1)] for _ in range(randrange(range_start, range_end + 1, 2)))
for _ in range(parens_num)
]
return random_parens
random_parens = get_random_walk_parens(1000, (2, 10))
random_parens[:10]
# output
[')(',
'(((())()',
')(((()()))',
'))))))',
'))())()(',
'))',
'(())',
')()(()()()',
')()())))((',
'()']
is_valid_evals = [str(isValid(random_paren)) for random_paren in random_parens]
len_evals = [len(random_paren) for random_paren in random_parens]
fig = px.histogram(is_valid_evals, title="Count of is-balanced for random walk parentheses strings")
fig.show()
Data Generation Scheme #2: Greedy Random Nesting Sequence
We can break down the construction of a balanced parentheses string into discrete units of nested parentheses. For this greedy construction, at each step in the process of generating a string a nesting depth is chosen from a basket of viable depths (to respect the target string length.)
For example for target length 6, the following unique nesting decompositions are possible:
-> [2, 1], [1, 2], [1,1,1] or [3]
Corresponding to:
-> (())(), ()(()), ()()(), ((()))
def get_balanced_parens(nest_depth: int) -> str:
"""Generate parentheses at the required nesting depth."""
return (PARENS[0] * nest_depth) + (PARENS[1] * nest_depth)
assert get_balanced_parens(3) == '((()))'
def get_balanced_sequence_parens(nest_depth_sequence: List[int]) -> str:
"""Return a parentheses string following the nesting depth sequence from a given list."""
return ''.join(get_balanced_parens(nest_depth) for nest_depth in nest_depth_sequence)
assert get_balanced_sequence_parens([1,1,2,3]) == '()()(())((()))'
def get_random_depth_sequence(target_paren_len: int) -> List[int]:
depth_sequence = []
while target_paren_len > 0:
depth = randint(1, target_paren_len / 2)
depth_sequence.append(depth)
target_paren_len -= 2 * depth
return depth_sequence
rand_depth_seq = get_random_depth_sequence(10)
print(rand_depth_seq)
# Example output: '[3, 1, 1]'
assert sum([2 * depth for depth in rand_depth_seq]) == 10
def get_random_sequence_parens(parens_num: int, length_range: Tuple[int]) -> List[str]:
random_depth_sequences = [get_random_depth_sequence( randrange(*length_range, 2) ) for _ in range(parens_num)]
random_parens = [
get_balanced_sequence_parens(random_depth_sequence) for random_depth_sequence in random_depth_sequences
]
return random_parens, random_depth_sequences
Get Balanced Parens
random_seq_parens, depth_sequences = get_random_sequence_parens(100000, (2, 11))
is_valid_evals = [str(isValid(random_paren)) for random_paren in random_seq_parens]
len_evals = [len(random_paren) for random_paren in random_seq_parens]
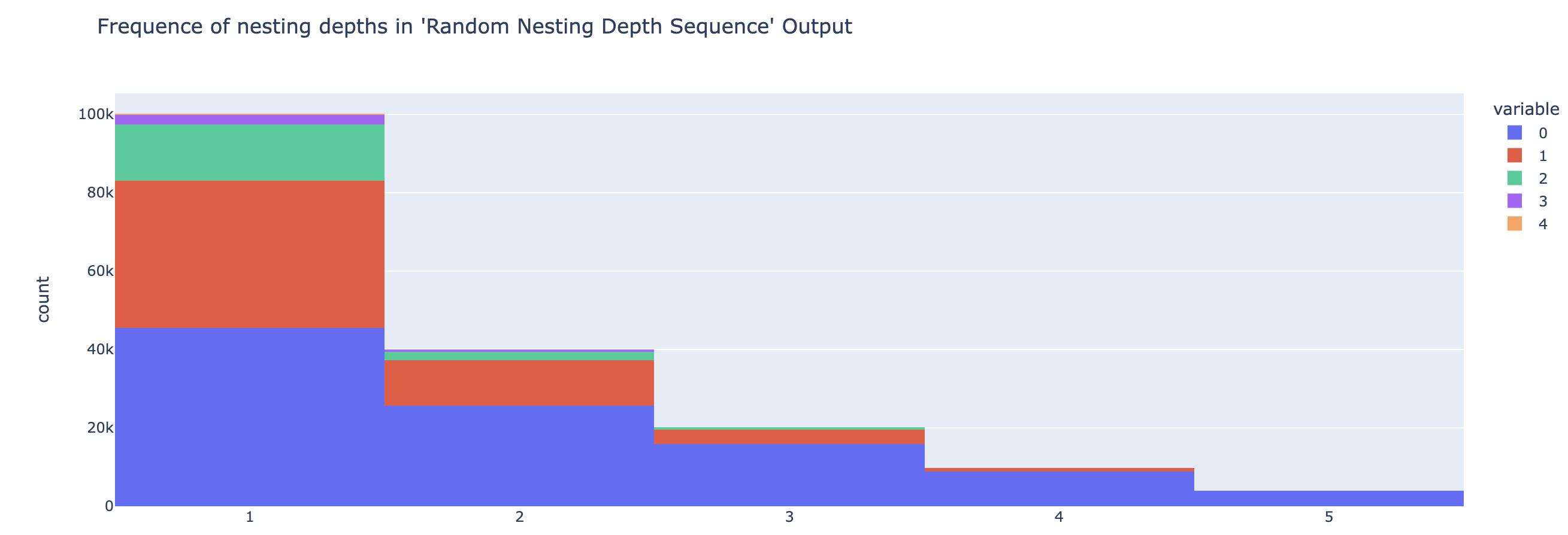
Let’s see the frequencies of nesting depths
depth_freq = {}
for seq in depth_sequences:
for depth in seq:
depth_freq.setdefault(depth, 0)
depth_freq[depth] += 1
depth_freq
# output -> {2: 39814, 1: 100088, 3: 20127, 4: 9908, 5: 4012}
depth_seq_hist = px.histogram(depth_sequences, title="Frequence of nesting depths in 'Random Nesting Depth Sequence' Output")
depth_seq_hist.show()
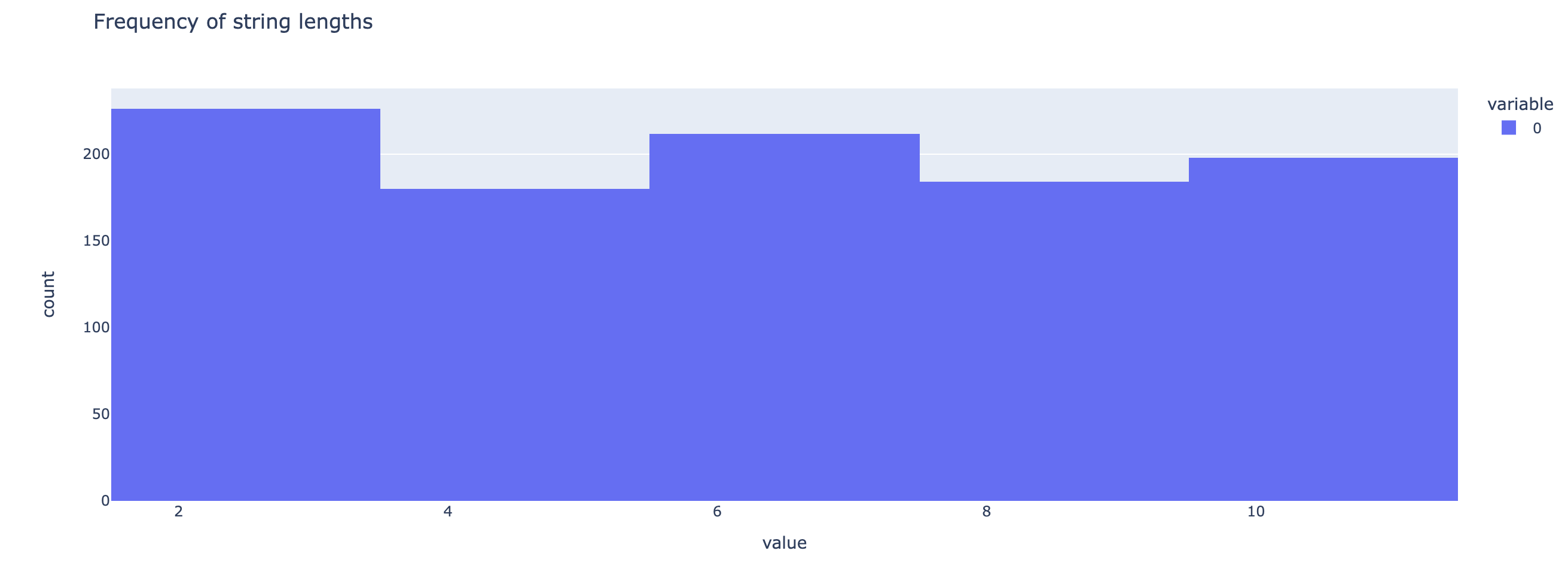
And now, to see the length frequencies.
paren_len_hist = px.histogram(len_evals, title="Frequency of string lengths")
paren_len_hist.show()
Data Generation Note
Note that there is a tension between the following potential properties of our data distribution.
- Every string length is equally likely.
- Every nesting depth substring is equally likely across all strings.
This is because low nesting-depth sub-sequences are going to have more opportunities to show up in a given random nesting sequence, as shown in the plots above.
To counter this natural tendency of the purely random sequence, when generating a given substring of parentheses, we could sample from a distribution skewed to make deeper nest values more likely.
This will be revisited after a first pass at training.
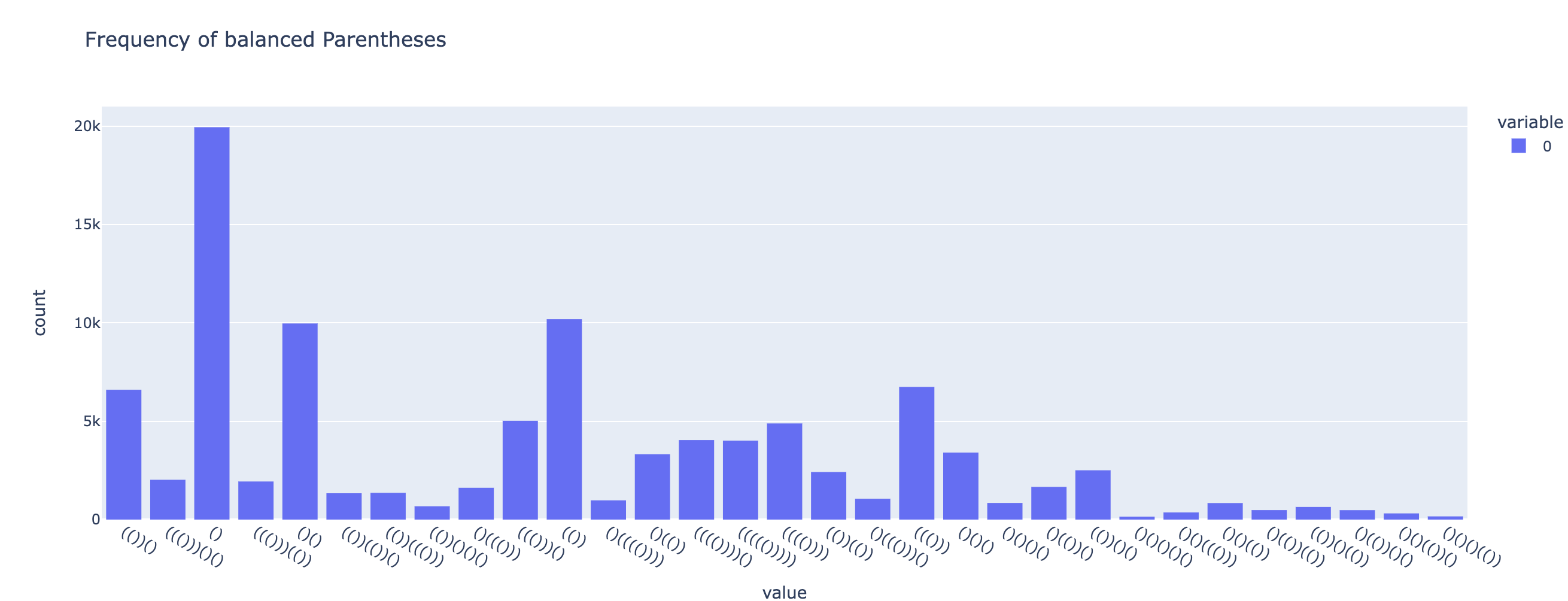
px.histogram(random_seq_parens, title="Frequency of balanced Parentheses").show()
Creating Unbalanced Parentheses
Our dataset can’t have only balanced parenthesis. So we can create a data generation strategy to derive unbalanced strings from our balanced dataset.
def _flip_idx(idx):
return (idx + 1) % 2
assert _flip_idx(0) == 1
assert _flip_idx(1) == 0
def make_parens_unbalanced(paren: str) -> str:
"""Take balanced-parentheses and randomly mutate it till it's unbalanced.
Both the number of mutations and indices are chosen at random.
"""
paren_idx_dict = {'(': 0, ')': 1}
paren_list = list(paren)
num_flipped_positions = randint(1, len(paren))
while isValid(''.join(paren_list)):
flip_points = sample(range(len(paren)), num_flipped_positions)
for flip_idx in flip_points:
idx_char = paren_idx_dict[paren_list[flip_idx]]
flipped_idx = _flip_idx(idx_char)
paren_list[flip_idx] = PARENS[flipped_idx]
return ''.join(paren_list)
assert not isValid(make_parens_unbalanced('((()))'))
Get UnBalanced Parens Dataset
unbal_random_seq_parens = [make_parens_unbalanced(paren) for paren in random_seq_parens]
Model Training
Now we have our datasets, for the fun of it, we’re going to write our Transformer architecture from scratch.
First some configs
@dataclass
class Config:
context_len = 12
d_vocab: int = 5
d_out_vocab: int = 2
d_model: int = 56
d_head = 28
d_mlp = 56 * 4
causal_attention = False
num_heads = 2
num_layers = 3
init_range: float = 1
PAD_TOKEN_IDX = 1
Then our tokenizer for parsing inputs:
class Tokenizer:
def __init__(self, vocab: str, context_width: Int, enforce_context: bool=False):
self.START_TOKEN, START_TOKEN_IDX = "<start>", 0
self.PAD_TOKEN, PAD_TOKEN_IDX = "<pad>", 1
self.END_TOKEN, END_TOKEN_IDX = "<end>", 2
util_tokens_t_to_i = {self.START_TOKEN: START_TOKEN_IDX, self.PAD_TOKEN: PAD_TOKEN_IDX, self.END_TOKEN: END_TOKEN_IDX}
util_tokens_i_to_t = {START_TOKEN_IDX: self.START_TOKEN, PAD_TOKEN_IDX: self.PAD_TOKEN, END_TOKEN_IDX: self.END_TOKEN}
self.enforce_context = enforce_context
self.context_width = context_width
self.vocab = vocab
self.t_to_i = {**util_tokens_t_to_i, **{token: token_id + 3 for token_id, token in enumerate(self.vocab)}}
self.i_to_t = {**util_tokens_i_to_t, **{token_id + 3: token for token_id, token in enumerate(self.vocab)}}
@staticmethod
def pad_sequence(sequence: str, end_token: str, pad_token: str, max_length: Int, enforce_context: bool) -> List[str]:
if not enforce_context:
# Truncate if sequence length is greater
sequence = sequence[:max_length]
else:
assert len(sequence) <= max_length, f"Sequence length is greater than the max allowed data length: {max_length}"
return list(sequence) + [end_token] + [pad_token] * (max_length - len(sequence))
def tokenize(self, data: Union[str, List[str]]) -> Int[Tensor, "batch seq"]:
if isinstance(data, str):
data = [data]
def _list_tokens_to_id(tokens: List[str]) -> List[Int]:
return [self.t_to_i[token] for token in tokens]
# to leave room for start and end tokens
max_seq_len = self.context_width - 2
data_as_tokens = [
_list_tokens_to_id([
self.START_TOKEN,
*self.pad_sequence(seq, self.END_TOKEN, self.PAD_TOKEN, max_seq_len, self.enforce_context),
])
for seq in data
]
return t.tensor(data_as_tokens)
(Un)Embeddings
class EmbedLayer(t.nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.W_E = t.nn.Parameter(t.empty(cfg.d_vocab, cfg.d_model))
t.nn.init.normal_(self.W_E, mean=0.0, std=cfg.init_range)
def forward(self, x: Int[Tensor, "batch seq"]) -> Int[Tensor, "batch seq d_model"]:
return self.W_E[x]
class UnEmbedLayer(t.nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.W_U = t.nn.Parameter(t.empty(cfg.d_model, cfg.d_out_vocab))
t.nn.init.normal_(self.W_U, mean=0.0, std=cfg.init_range)
def forward(self, x: Int[Tensor, "batch seq d_model"]) -> Int[Tensor, "batch seq d_out_vocab"]:
return x @ self.W_U
class PositionalEmbedding(t.nn.Module):
def __init__(self, cfg: Config):
super().__init__()
denom = t.exp(
t.arange(0, cfg.d_model, 2) * -(math.log(10000.0) / cfg.d_model)
)
pos = t.arange(0, cfg.context_len).unsqueeze(1)
param = pos * denom
P_E = t.zeros(cfg.context_len, cfg.d_model)
P_E[:, 0::2] = t.sin(param)
P_E[:, 1::2] = t.cos(param)
P_E = P_E.unsqueeze(0)
self.register_buffer("P_E", P_E)
def forward(self, x):
_batch, seq_len, d_model = x.shape
x = x + self.P_E[..., :seq_len, :d_model].requires_grad_(False)
return x
Handy Layer Norm
class LayerNorm(t.nn.Module):
def __init__(self, cfg):
super().__init__()
self.scale = t.nn.Parameter(t.ones(cfg.d_model))
self.bias = t.nn.Parameter(t.zeros(cfg.d_model))
def forward(self, x):
mean = t.mean(x, dim=2, keepdim=True)
var = t.var(x, dim=2, keepdim=True, unbiased=False)
y = (x - mean) / (var + 0.00001).sqrt()
return (y * self.scale) + self.bias
And finally Attention!
class AttentionLayer(t.nn.Module):
def __init__(self, cfg):
super().__init__()
self.register_buffer("IGNORE", t.tensor(-1e5, dtype=t.float32))
self.cfg = cfg
self.W_Q = t.nn.Parameter(t.empty(cfg.num_heads, cfg.d_model, cfg.d_head))
self.W_K = t.nn.Parameter(t.empty(cfg.num_heads, cfg.d_model, cfg.d_head))
self.W_V = t.nn.Parameter(t.empty(cfg.num_heads, cfg.d_model, cfg.d_head))
self.W_O = t.nn.Parameter(t.empty(cfg.num_heads, cfg.d_head, cfg.d_model))
self.b_Q = t.nn.Parameter(t.zeros(cfg.num_heads, cfg.d_head))
self.b_K = t.nn.Parameter(t.zeros(cfg.num_heads, cfg.d_head))
self.b_V = t.nn.Parameter(t.zeros(cfg.num_heads, cfg.d_head))
self.b_O = t.nn.Parameter(t.zeros(cfg.d_model))
t.nn.init.normal_(self.W_Q, mean=0.0, std=cfg.init_range)
t.nn.init.normal_(self.W_K, mean=0.0, std=cfg.init_range)
t.nn.init.normal_(self.W_V, mean=0.0, std=cfg.init_range)
t.nn.init.normal_(self.W_O, mean=0.0, std=cfg.init_range)
def forward(self, params):
#TODO: revisit implementing pad_mask with hooks
x, pad_mask = params
Q = einops.einsum(x, self.W_Q, 'b s dm, h dm dh -> b s h dh') + self.b_Q
K = einops.einsum(x, self.W_K, 'b s dm, h dm dh -> b s h dh') + self.b_K
V = einops.einsum(x, self.W_V, 'b s dm, h dm dh -> b s h dh') + self.b_V
attention_scores = einops.einsum(Q, K, 'b s_q h dh, b s_k h dh -> b h s_q s_k')
scaled_attention_scores = attention_scores / (self.cfg.d_head ** 0.5)
if self.cfg.causal_attention:
scaled_attention_scores = self.apply_causal_mask(scaled_attention_scores)
scaled_attention_scores = self.apply_padding_mask(scaled_attention_scores, pad_mask)
attention_patterns = t.nn.Softmax(dim=-1)(scaled_attention_scores)
post_attention_values = einops.einsum(
attention_patterns,
V,
'b h s_q s_k, b s_k h dh -> b s_q h dh'
)
out = einops.einsum(
post_attention_values,
self.W_O,
'b s_q h dh, h dh dm -> b s_q dm'
) + self.b_O
return out
def apply_causal_mask(self, attention_scores):
b, h, s_q, s_k = attention_scores.shape
mask = t.tril(t.ones(s_q,s_k)).bool()
return t.where(mask, attention_scores, self.IGNORE)
def apply_padding_mask(self, attention_scores, pad_mask):
return t.where(pad_mask, attention_scores, self.IGNORE)
MLP Layers
class LinearLayer(t.nn.Module):
def __init__(self, in_dim, out_dim, include_bias=True):
super().__init__()
self.include_bias = include_bias
self.W = t.nn.Parameter(t.empty(in_dim, out_dim))
t.nn.init.normal_(self.W, mean=0.0, std=cfg.init_range)
self.b = None
if include_bias:
self.b = t.zeros(out_dim)
def forward(self, x: Int[Tensor, "batch seq in_dim"]) -> Int[Tensor, "batch seq out_dim"]:
out = x @ self.W
if self.include_bias:
out = out + self.b
return out
class MLP(t.nn.Module):
def __init__(self, cfg):
super().__init__()
self.in_layer = LinearLayer(cfg.d_model, cfg.d_mlp)
self.out_layer = LinearLayer(cfg.d_mlp, cfg.d_model)
self.non_linearity = t.nn.ReLU()
def forward(self, x):
post_W_in = self.in_layer(x)
post_non_lin = self.non_linearity(post_W_in)
return self.out_layer(post_non_lin)
Putting it together into a Transformer
class TransformerBlock(t.nn.Module):
def __init__(self, cfg):
super().__init__()
self.ln1 = LayerNorm(cfg)
self.attention = AttentionLayer(cfg)
self.ln2 = LayerNorm(cfg)
self.mlp = MLP(cfg)
def forward(self, params):
x, pad_mask = params
resid_mid = self.attention((self.ln1(x), pad_mask)) + x
resid_post = self.mlp(self.ln2(resid_mid)) + resid_mid
return resid_post, pad_mask
class Transformer(t.nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
self.embed = EmbedLayer(cfg)
self.pos_embed = PositionalEmbedding(cfg)
self.final_ln = LayerNorm(cfg)
self.unembed = UnEmbedLayer(cfg)
self.blocks = t.nn.Sequential(*([TransformerBlock(cfg)] * cfg.num_layers))
def forward(self, x):
#TODO: revisit implementing pad_mask with hooks
pad_mask = self.get_pad_mask(x)
res_post_pos_embed = self.pos_embed(self.embed(x))
post_blocks, _ = self.blocks((res_post_pos_embed, pad_mask))
logits = self.unembed(self.final_ln(post_blocks))
return logits
def get_pad_mask(self, x):
batch, seq = x.shape
return einops.repeat(x != self.cfg.PAD_TOKEN_IDX, 'batch seq -> batch 1 seq_q seq', seq_q=seq)
Training utils
def cross_entropy_loss(output, targets):
log_probs = output.log_softmax(dim=-1)
predictions = log_probs[:, 0]
batch, out_dim = predictions.shape
true_output = predictions[range(batch), targets]
return -true_output.sum() / batch
def test(model, data, loss_func):
inputs, targets = data
with t.no_grad():
output = model(inputs)
loss = loss_func(output, targets)
return loss
def train(model, data, optimizer, loss_func):
inputs, targets = data
optimizer.zero_grad()
output = model(inputs)
loss = loss_func(output, targets)
loss.backward()
optimizer.step()
return loss
Training config
cfg = Config()
tokenizer = Tokenizer('()', 12, True)
inputs = tokenizer.tokenize([*unbal_random_seq_parens, *random_seq_parens])
targets = t.tensor([*([0] * len(unbal_random_seq_parens)), *([1] * len(random_seq_parens))])
rand_indices = t.randperm(targets.shape[0])
rand_inputs = inputs[rand_indices, :]
rand_targets = targets[rand_indices]
model = Transformer(cfg)
adamW = t.optim.AdamW(model.parameters(), lr=0.01)
Actual Training
batch_size = 10000
train_size = int(0.7 * batch_size)
epochs = 15
for epoch in range(epochs):
for batch_id in range(0, rand_inputs.shape[0], batch_size):
rand_inputs_batch, rand_targets_batch = rand_inputs[batch_id : batch_id + batch_size], rand_targets[batch_id : batch_id + batch_size]
train_input, train_target = rand_inputs_batch[:train_size, :], rand_targets_batch[:train_size]
test_input, test_target = rand_inputs_batch[train_size:, :], rand_targets_batch[train_size:]
train(model, (train_input, train_target), adamW, cross_entropy_loss)
test_loss = test(model, (test_input, test_target), cross_entropy_loss)
print(f'Loss: {test_loss} on epoch: {epoch}/{epochs}')

In Part 3, we’ll investigate the internals of this trained network. We’ll do this by looking at attention patterns and applying some of the diagnostic tools of Mechanistic interpretability such as activation patching to build a mechanistic model of understanding how the network has solved this task.
Thanks for reading this far and catch you soon in Part 3!